
เสิร์ชเอนจิน – Search Engines คืออะไร, ทำงานยังไง, มีประโยชน์อย่างไร สอนครบจบทุกมิติ
![]()
ถ้าผมถามคุณว่า วันนี้คุณใช้ Search Engine ไปกี่ครั้งแระ?
ผมอาจจะไม่ได้คำตอบกลับมา อืมม์.. งั้นลองเปลี่ยนคำจาก search engine ไปเป็น Google แล้วกัน อันนี้ต้องร้อง อ๋อออ กันยาวๆ เลยทีเดียว
ในทางทฤษฎี Google..
ก็คือหนึ่งใน เสิร์ชเอนจิน (หรือ Search Engine) ที่มีอยู่นับสิบในโลกใบนี้ แต่ด้วยความนิยมด้วยมั้ง คนเลยเหมารวมว่า search engine ก็คือ กูเกิ้ล ไปโดยปริยาย
ถามต่อไปว่า ใช้งานลูกพี่กรู (เกิ้ล) หายาลดความอ้วน, หาแฟน, หาโน่น นี่ นั่น อยู่ทุกวันๆ ละหลายครั้ง เคยสงสัยมั่งไหมว่า เอ๊ะ.. เสิร์ชเอนจิน มันทำงานกันยังไง แล้ว ผลลัพธ์ที่ได้ (จากการค้นหาอะไรบางอย่าง) มีตั้งเป็นล้านๆ เว็บ ไอ้เว็บที่อยู่ลำดับที่ 1 หรือ ที่ 2 .. นี่มันหามาได้ยังไง มีหลักการอะไร
วันนี้ผมรับอาสานำพาคุณไปทำความเข้าใจในมิติที่คุณยังไม่เคยรู้ (หรือไม่เคยอยากที่จะต้องการรู้ ก็สุดแท้แต่ เหอๆ..) เกี่ยวกับ search engines ถ้ายังไม่มีอะไรทำในตอนนี้ หรือต้องการหาอะไรทำฆ่าเวลา ก็ขอเรียนเชิญอ่านบทความนี้ไปพร้อมๆ กัน
เสิร์ชเอนจิน คืออะไร มีกี่ประเภท
เรามาดูความหมายของ search engine กันแบบบ้านๆ ก่อน แปลตรงตัวทีละคำ Search แปลว่า ค้นหา เป็นคำกริยา (หรือ Verb) ส่วน Engine ก็คือ เครื่องกล, เครื่องจักรกล, หรือ เครื่องยนต์กลไก อะไรเทือกนี้ เอาสองคำมารวมกัน แปลตามประสาผม
Search Engine หมายถึง เครื่องมือ (ซอร์ฟแวร์) ที่มีฐานข้อมูลของคำค้นหาอยู่ พอคุณต้องการหาอะไร ก็ส่งคำค้นหาให้กับ Softwae ประเภทนี้ มันก็จะส่งผลลัพธ์ของการค้นหานั้นๆ คืนกลับมา
ในปัจจุบัน มี เสิร์ชเอนจินอยู่หลายตัว หลายประเภทด้วยกันใน internet แต่ละตัวก็มีความสามารถแตกต่างกันไป search engine ตัวแรกถูกสร้าง และพัฒนาขึ้นก็คือ Archie (มาจากคำว่า Archive) เขียนขึ้นโดย Alan Emtage, Bill Heelan, และ Mike Parker จากมหาวิทยาลัย Montreal ประเทศแคนาดา เพื่อใช้ในการค้นหาไฟล์ประเภท FTP และ มีการปล่อยให้ใช้งานเมื่อวันที่ 10 กันยายน 1990
search engine ที่เป็น text based หรือ ค้นหาด้วยตัวหนังสือตัวแรกของโลก มีชื่อว่า Veronica (ย่อมาจาก Very Easy Rodent-Oriented Net-wide Index to Computer Archives) ในปัจจุบัน search engines ที่มีความนิยมใช้กันได้แก่ AOL, Ask.com, Baidu, Bing, Yahoo และที่ขาดไม่ได้ นิยมมากที่สุด ก็คือ Google
ณ ปัจจุบัน search engines ได้ถูกแบ่งออกเป็น 3 ประเภทตามหลักการทำงาน ดังนี้
1. Crawler based หรือแบบที่ใช้ตัวไต่
Search Engine ชนิดแรกเป็นประเภทใช้ software ที่เขียนขึ้นมาเรียกว่ ตัวไต่ (web crawler )
Web Crawler คือ Bots, หรือ แมงมุม (Spider) ที่เว็บ search engine ส่งไปไต่เว็บไซต์ต่างๆ บนอินเตอร์เน็ต แล้วนำข้อมูลเกี่ยวกับเว็บต่างๆ มาเก็บไว้ในฐานข้อมูล
รายละเอียดการทำงานหลักๆ แบ่งเป็น 4 ขั้นตอน ดังนี้
- Crawling: การไต่เว็บใน internet โดย bots แล้วนำข้อมูลมาบันทึกไว้ในฐานข้อมูล
- Indexing: การจัดดัชนีเว็บเพจ ว่าเพจไหนเกี่ยวกับอะไร มีคีย์เวิร์ดอะไร
- Calculating Relevancy: การคำนวณว่าเว็บไหนเหมาะสม และตรงกับคำค้นหาไหน
- Retrieving the Result: การดึงข้อมูลในดัชนีเว็บมาแสดงผล ในหน้าผลลัพธ์การค้นหา
ในหัวข้อนี้ขอเกริ่นคร่าวๆ ไว้เพียงเท่านี้ เพราะยังมีอีก 2 ประเภท seach engines ทีต้องพูดถึงกัน การทำงานแบบละเอียดของ crawler เดี๋ยวเรามาอ่านกันให้ตาแฉะ อีกทีในหัวข้อ “เสิร์ชเอนจินทำงานยังไง?”
2. เว็บไดเร็กทอรี่
ประเภทต่อไปของ search engine ประเภทที่สอง ก็คือ เว็บไดเร็กทอรี่ที่อาศัยแรงคน เป็นหลัก ในการจัดทำดัชนี หลักการทำงานไม่สลับซับซ้อนเหมือนแบบแรก
- เจ้าของเว็บ ฝากรายละเอียดเว็บไซต์กับผู้ให้บริการเว็บไดเร็กทอรี่ ผู้ใช้งานจะได้มาหาเว็บตนเจอ โดยใส่คำจำกัดความสั้นๆ แล้วก็เลือกหมวดหมู่ที่ต้องการ
- จากนั้น เจ้าของ directoy ก็จะมาตรวจสอบความเหมาะสม ว่าเข้าเกณฑ์ไหม ถ้าเขาคิดว่าไม่เหมาะ ก็มีสิทธิ์ที่ปฏิเสธคุณได้ ดังนั้นถ้าเว็บคุณเป็นเว็บที่ดี เต็มไปด้วยเนื้อหาคุณภาพ มีประโยชน์ต่อผู้ใช้ โอกาสที่จะได้รับการอนุมัติก็มีสูงเป็นเงาตามตัวไปด้วย
- ถ้าใน description หรือคำจำกัดความที่คุณได้ใส่ไว้ มีคีย์เวิร์ดที่ผู้ใช้ๆ ในการค้นหา เว็บของคุณก็จะถูกแสดงเป็นหนึ่งในผลลัพธ์การค้นหา
ไดเท็กทอรี่ที่ดังๆ สมัยก่อน ยกตัวอย่าง เช่น Yahoo, หรือ DMOZ แต่เดี๋ยวนี้ความต้องการใช้งานลดน้อยถอยลงไปมาก ผู้คนส่วนใหญ่หันมาใช้ search engines ที่ใช้ bots กันเสียมากแล้วทุกวันนี้
3. แบบลูกผสม (Hybrid)
search engine ชนิดสุดท้ายที่จะกล่าวกันในบทความนี้เป็น ลูกครึ่งครับ กล่าวคือ จะใช้ตัวไต่ แล้วก็ใช้คนด้วย ในการทำ index
ที่ผ่านมาในอดีตเสิร์ชเอนจินแบบทีใช้ตัวไต่ บางครั้งก็จะใช้คนทำงานด้วย เช่น Google ถึงจะใช้ bots เป็นกลไกหลักในการทำงาน แต่ก็มีบ้างที่ไปดึง คำจำกัดความของเว็บ (description) มาจากไดเร็กทอรี่ แล้วนำมาแสดงในผลลัพท์การค้นหา หรือ SERP
อย่างไรก็ตามเมื่อความนิยมในการใช้ directories น้อยลง search engines ที่ทำงานแบบ Hybrid ก็ค่อยๆ ลดบทบาทของคนลง คือ จะไปเน้นใช้ spider กันมากกว่า
เสิร์ชเอนจินทำงานยังไง?
มาดูคำ Matt Cutts จาก Google อธิบายว่า search engine ทำงานยังไงกันก่อน
ดูเสร็จแล้วถ้ายังไม่เข้าใจ อ่านคำอธิบายภาษาไทยด้านล่าง ว่าการทำงานของ search engine มีกี่ขั้นตอน และแต่ละขั้นตอนมีรายละเอียดยังไงบ้าง
1. Crawling
การทำงานในขั้นตอนแรกนี้ คือ การไต่ (Crawling) อย่างที่ได้แตะไว้แล้วหน่อยนึงว่า Search Engine ก็จะส่งลูกน้องมือดี คือ Spider (แมงมุมน้อยตัวนั้น ..) มาไต่เว็บคุณ และเว็บอื่นๆ ใน internet ด้วย
ความถี่ (Frequency) ในการไต่ ไม่แน่นอน ไม่เหมือนกันแล้วแต่ค่ายของเสริชเอ็นจิ้น บางเจ้าก็ไต่ช้า บางเจ้าไต่เร็ว พอไต่เว็บคุณไปครั้งนึง อาจทิ้งช่วงเว้นสัก 2-3 วัน ก่อนที่จะแวะเวียนกลับมาเยี่ยมคุณอีกครั้ง ถึงตรงนี้คุณอาจเคยสังเกตว่า..
“เอ๊ะ! หน้าที่ลบทิ้งไปแล้ว ทำไหม ยังอยู่ใน search engine อีกล่ะวุ้ย? ..”
ก็เพราะนี้แหละครับ มันทิ้งช่วง คุณต้องรอให้ bots มาไต่เว็บคุณอีกที ข้อมูลการเปลี่ยนแปลงล่าสุดบนเว็บคุณถึงจะถูกส่งกลับไป update
2. Indexing
ขั้นตอนต่อไปคือ Indexing ก็คือกระบวนการหลังจากการไต่เสร็จ search engines ก็จะพยายามทำความเข้าใจหน้าเว็บต่างๆ ว่าเกี่ยวกับอะไร และก็จะทำการระบุคำหลัก (Keyword) ที่มีในแต่ละหน้า จัดทำดัชนีเพจ (Indexing) แล้วเก็บในฐานข้อมูล
กับคำกล่าวที่ว่า”ไม่มีอะไรสมบูรณ์แบบ” คำๆ นี้ใช้ได้เสมอกับทุกสิ่งอย่าง แม้แต่กับเสริชเอ็นจิ้นท์ที่ทันสมัยที่สุด กล่าวคือ บางครั้ง search engine เองก็พยายามตีความ web sites อย่างดีทีสุดแล้ว ว่าหน้าที่มันได้ข้อมูลมานั้นเกี่ยวกับอะไร ก็ยังไม่ค่อยตรงกับสิ่งที่เจ้าของเว็บ หรือ web master ต้องการจะสื่อสักเท่าไร
อันนี้คุณในฐานะเจ้าของเว็บ ก็ควรทำการปรับแต่งหน้าเว็บให้ถูกต้องตามหลักการทำ SEO กันให้ดี เพื่อที่จะไม่ให้ Search engines เขาต้องเดามากไป เพราะอาจผลกระทบต่อ ranking ตามมา
3. Calculating Relevancy
ในขั้นตอนนี้ serch engines จะทำการเปรียบเทียบ “คำที่คนใช้ในการค้นหา” กับ “ดัชนีหน้าเพจ” ที่ได้ทำไว้ก่อนหน้า และโดยมากจะมีมากกว่าหนึ่ง web pageในฐานข้อมูลที่ match หรือ ตรงกับคำค้นหา ดังนั้นเสิร์ชเอนจินก็จะทำการคำนวณ (Calculating Relevancy) ออกมาว่า หน้าไหนน่าจะมีเนื้อหาที่ตรงใจกับ ผู้ค้นหามากที่สุด ในขั้นตอนนี้
4. Retrieving the Result
step สุดท้ายในการทำงานของ เสิร์ชเอนจินก็คือ การดึงข้อมูลมาแสดงผลใน SERP หรือ Search Engine Result Pages โดยจะจัดเรียงผลลัพธ์ตาม Relevancy หรือ ความแม่นตรง กับคำที่คุณใช้ค้นหา
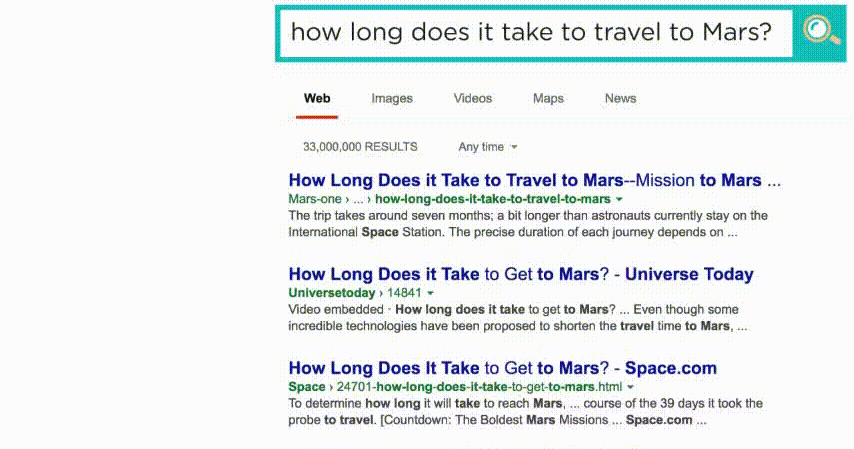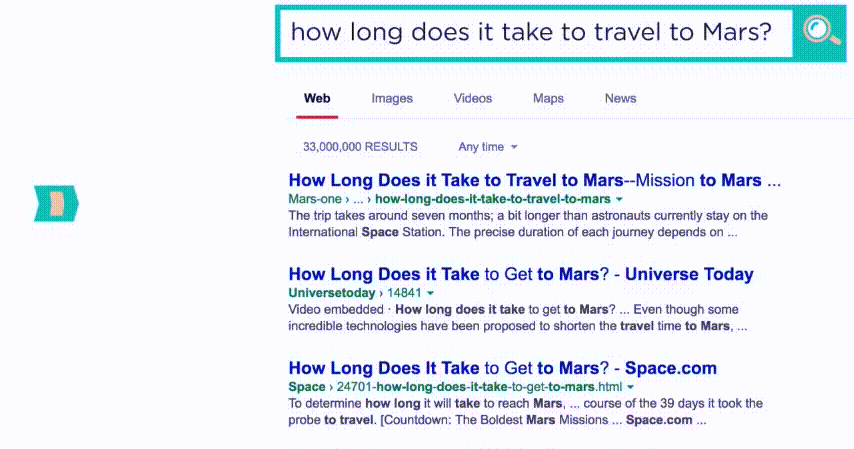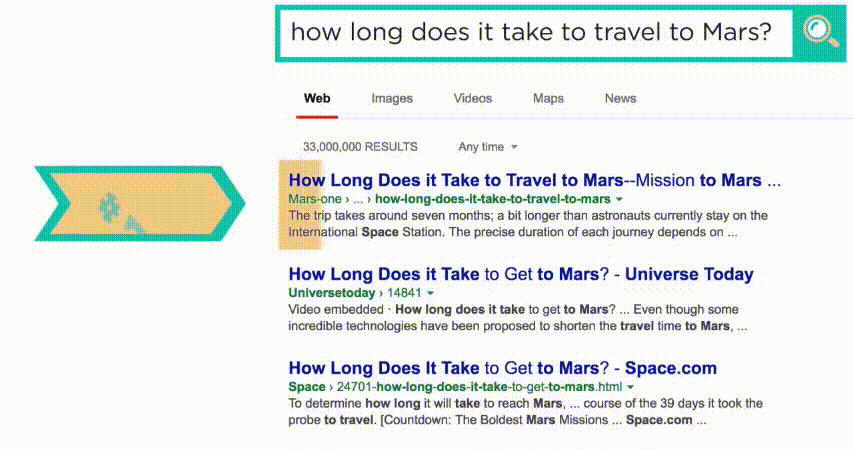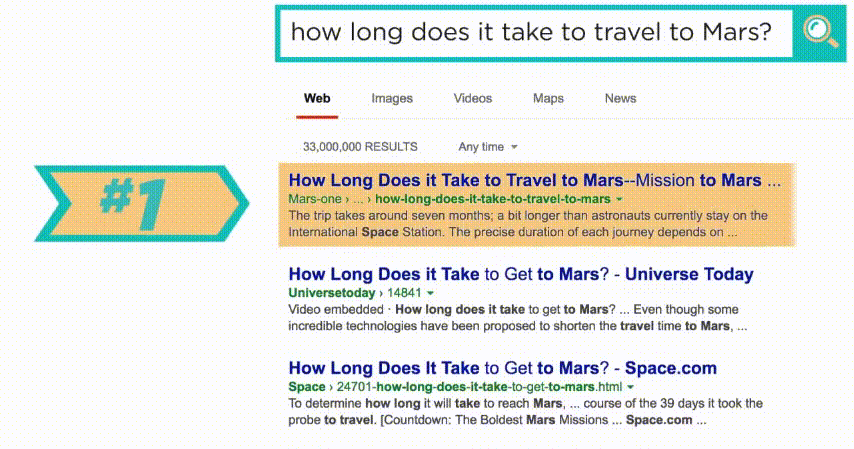
เว็บที่คำนวณออกมาแล้ว และคิดว่าตรงกับคำค้นหามากที่สุด จะถูกวางไว้อันดับหนึ่ง ในหน้าผลลัพธ์การค้นหา
ประโยชน์ของ search engine มีอะไรบ้าง?
จากสถิติในอินเตอร์เน็ทนั้น มีเว็บไซต์ (ที่ยังใช้งานได้) อยู่มากกว่า 625 ล้านเว็บ! ถ้าไม่มี Goolge หรือ Bing เวลาต้องการหาข้อมูลออะไรสักอย่าง เห็นทีจะต้องสิ้นเปลืองเวลาชีวิตกันมากโขอยู่ ในหัวข้อนี้เรามาดูประโยชน์หลักๆ ที่เราได้จาก search engines กัน
1. ประหยัดเวลา
ถาม: สมัยก่อนตอนที่ยังไม่มี internet เวลาที่คุณต้องการหาข้อมูล ทำยังไงครับ?
ตอบ: สมุดหน้าเหลือง! ก็ไล่เปิดไปสิ แล้วก็โทรไปถามสิ (ถึกมาก)ถาม: สมัยก่อนตอนที่มี internet แล้ว แต่ยังไม่มี Google หรือ Yahoo เวลาที่คุณต้องการหาอะไรทำยังไงครับ?
ตอบ: ก็ต้องไล่เข้าไปทีละเว็บ เช็คไปกว่าจะเจอเว็บที่มีเนื้อหาตรงใจ
สรุปคือ เสียเวลามากกก ถ้าเราไม่มี search engines
ทุกวันนี้จะหาอะไรที แป๊ปเดียวเสร็จ บางทีหา 10 อย่างใน 5 นาที ก็ยังหาเจอ
2. ความแม่นยำ
ได้พูดกันไปบ้างแล้วเรื่องการคำนวณความแม่น ของ search engines ตอนนี้เรามาดูตัวอย่างให้เห็นภาพกันดีกว่า ว่าเขาแม่นยังไง
สมมุติว่าคุณหิว และอยากกินพิซซ่า คุณก็เปิด Google แล้วพิมพ์คำว่า “พิซซ่า” ลงไป ผลลัพธ์ที่ได้ในหน้า 1 เต็มไปด้วยเว็บขาย Pizza ที่คุณสามารถโทรสั่ง (เช่น 1112) หรือสั่งออนไลน์ให้มาส่งถึงบ้านก็ได้
ต่อไปเป็นผลลัพธ์หน้า 3 ของกูเกิืล เป็นหน้าเพจที่มีรูปพิซซ่าเต็มไปหมด ให้เลือกโหลดมาใช้งาน

ลองจินตนาการดูนะครับ ถ้าหน้าแรกของผลการค้นหาเต็มไปด้วยเว็บ download รูป pizza ในขณะที่คุณอยากบริโภคฮาวายเอี่ยนสักถาดนึง แบบนี้อาจมีถอดใจกันบ้าง ต้องปั่นจักรยานไปซื้อก๋วยจั๊บ ที่ปากซอย มาซดประทังชีวิตไปก่อน ก็เป็นได้
3. ความสามารถในการหาขั้นสูง
หลายท่านใช้งาน Google อยู่ทุกวันแต่ยังไม่ทราบว่า มีวิธีหาอะไรที่ซับซ้อนมากกว่าการที่ใส่ คำค้นหาลงไปเฉยๆ เช่น ถ้าคุณต้องการให้มีคำที่คุณต้องการค้นหาอยู่ใน URL ของเว็บด้วย คุณก็ใช้ search operator “inulr:”, หรือ ต้องการหาเว็บที่มีคำที่คุณต้องการ ให้อยู่ใน title ของหน้า คุณก็ใช้ “intitle:” เป็นต้น
4. ฟรี!
Search engines ยอดนิยมอย่าง Google หรือ Bing เองก็ดี จริงๆ แล้วไม่ฟรี !!

คือเขาเก็บตังค์นะครับ แต่ไม่ได้เก็บกับผู้ใช้ แต่ไปเก็บกับผู้ที่มาลงโฆษณา ดังนั้นเนี่ยในฐานะ user เรามีเครื่องมือค้นหาที่เจ๋งๆ ให้ใช้กันฟรีๆ ต้องยอมรับว่า ชีวิตดี๊ดี มีประโยชน์
10 ตัวอย่าง รายชื่อ Search Engine ยอดนิยม
ในหัวข้อนี้ขอยกตัวอย่างเว็บไซต์ search engine สัก 10 ราย ที่ชาวโลกเขานิยมใช้กันในปัจจุบัน เรียงตามลำดับความนิยมจากมากไปน้อย (ข้อมูลจาก eBiz ปี 2023)
 Google กูเกิ้ล search engine ยอดนิยม
Google กูเกิ้ล search engine ยอดนิยม
อันดับ 1 ของไทย และและของโลก
จำนวนผู้เข้าใช้งานต่อเดือน: 1,800,000,000
 Bing search engine ถูกสร้างโดยบริษัท Microsoft (เป็นที่รู้จักกันดีในนามของบริษํทที่ผลิตระบบปฏิบัติการ Windows)
Bing search engine ถูกสร้างโดยบริษัท Microsoft (เป็นที่รู้จักกันดีในนามของบริษํทที่ผลิตระบบปฏิบัติการ Windows)
Bing ถูกพัฒนาต่อยอดมาจาก MSN Search
จำนวนผู้เข้าใช้งานต่อเดือน: 500,000,000
 ยาฮู (Yahoo) เสริชเอ็นจิ้นเก่าแก่อีกตัวนึง มาก่อน Google เสียอีก สำนักงาน Yahoo ตั้งอยู่ที่ Sunnyvale, California ในวันที่ 29 มิถุนายน 2009 Yahoo ได้ตกลงกับ Bing ในการเอากลไกหลักในการให้บริการในฐานะ Seach engine
ยาฮู (Yahoo) เสริชเอ็นจิ้นเก่าแก่อีกตัวนึง มาก่อน Google เสียอีก สำนักงาน Yahoo ตั้งอยู่ที่ Sunnyvale, California ในวันที่ 29 มิถุนายน 2009 Yahoo ได้ตกลงกับ Bing ในการเอากลไกหลักในการให้บริการในฐานะ Seach engine
จำนวนผู้เข้าใช้งานต่อเดือน: 490,000,000
 Baidu เป็น search engine สัญชาติจีน
Baidu เป็น search engine สัญชาติจีน
เกิดขึ้นเมื่อวันที่ 18 มกราคม ปี 2000 สำนักงานใหญ่อยู่ที่ปักกิ่ง
จำนวนผู้เข้าใช้งานต่อเดือน: 480,000,000
 Ask เป็นเสริชเอ็นจิ้นของ Ask.com (เดิมรู้จักในชื่อของ Ask Jeeves) สร้างโดย Garret Gruener และ David Warthen ทั้ง 2 สร้าง Ask ขึ้นมา
Ask เป็นเสริชเอ็นจิ้นของ Ask.com (เดิมรู้จักในชื่อของ Ask Jeeves) สร้างโดย Garret Gruener และ David Warthen ทั้ง 2 สร้าง Ask ขึ้นมา
เพราะมีความเชื่อว่าผู้คนหาสิ่งต่างๆ ด้วยการตั้งคำถาม จึงเป็นที่มาของ Ask ซึ่งแปลเป็นไทยว่า ถาม นั่นเอง
จำนวนผู้เข้าใช้งานต่อเดือน: 300,000,000
 AOL เป็นเว็บท่า (Portal)
AOL เป็นเว็บท่า (Portal)
สัญชาติอเมริกัน ใน New York
จำนวนผู้เข้าใช้งานต่อเดือน: 200,000,000
 DuckDuckGo คือ Search Engine ที่ถูกสร้างขึ้นมาเพื่อเน้นการป้องกันเรื่องข้อมูลและความเป็นส่วนตัว (Privacy) ของผู้ใช้บริการ
DuckDuckGo คือ Search Engine ที่ถูกสร้างขึ้นมาเพื่อเน้นการป้องกันเรื่องข้อมูลและความเป็นส่วนตัว (Privacy) ของผู้ใช้บริการ
สร้างขึ้นโดย Gabriel Weinberg ในปี 2008
จำนวนผู้เข้าใช้งานต่อเดือน: 150,000,000
 Wolfram Alpha คือ search engine ที่มีหลักการมาจาก Computational Knowledge
Wolfram Alpha คือ search engine ที่มีหลักการมาจาก Computational Knowledge
ซึ่งก็คือเป็นเครื่องมือค้นหาที่สั่งสมคำตอบจากการถาม สร้างโดยบริษัท Wolfram Alpha
จำนวนผู้เข้าใช้งานต่อเดือน: 35,000,000
 Yandex เว็บให้บริการการค้นหาในอินเตอร์เน็ท อันดับ 1 ของชาวรัสเซีย คือราว 51.2% (ในปี 2015)
Yandex เว็บให้บริการการค้นหาในอินเตอร์เน็ท อันดับ 1 ของชาวรัสเซีย คือราว 51.2% (ในปี 2015)
สร้างขึ้นโดยบริษัท Yandex
จำนวนผู้เข้าใช้งานต่อเดือน: 30,000,000
 web crawler เว็บให้บริการ search ที่เก่าแก่ที่สุด (ที่ยังให้บริการอยู่) ให้บริการวันแรก ในวันที่ 20 เมษายน 1994
web crawler เว็บให้บริการ search ที่เก่าแก่ที่สุด (ที่ยังให้บริการอยู่) ให้บริการวันแรก ในวันที่ 20 เมษายน 1994
สร้างโดย Blucora หรือแต่ก่อนรู้จักกันในชื่อ Infospace
จำนวนผู้เข้าใช้งานต่อเดือน: 25,000,000
ส่วนแบ่งการตลาดเว็บไซต์ที่ให้บริการเสิร์ชเอนจิ้นในประเทศไทย
ในไทยเอง ที่นิยมใช้ก็จะเป็น Google.co.th ได้รับความนิยมมากที่สุด คือ ประมาณ 99% (ปี 2018)
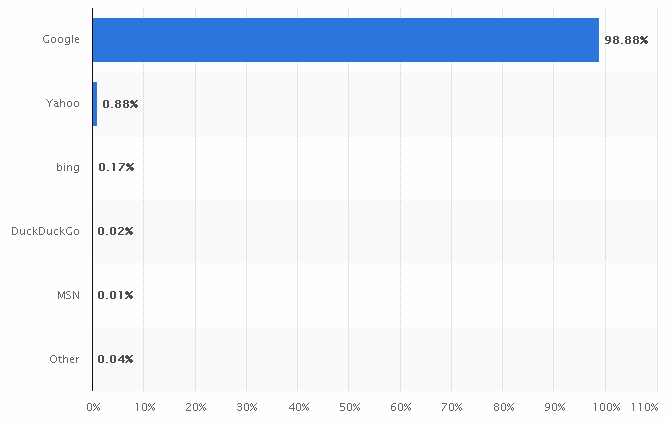
ตามมาแบบห่างๆ อันดับ 2 และ 3 คือ Yahoo, และ Bing ตามลำดับ โดยมี market share รวมกันแล้วได้ประมาณ 1% เท่านั้น




